
Distributed Training Part 2: Parallel Programming
Distributed Training Part 2: Parallel Programming
- Broadcast
- Reduce & AllReduce
- Gather & AllGather
- Scatter & ReduceScatter
0. Point-to-Point Communication vs. Collective Communication
Point-to-Point Communication is a network communication model in which two or more computers or devices communicate directly with each other without going through a central server or centralized system. In this model, each participant can act as both a client and a server, capable of directly exchanging information or sharing resources with other nodes.
Collective Communication refers to the process in which a group of computing nodes or processing units collaborate, exchange information, or perform communication operations together. This type of communication involves the collective participation of multiple nodes, rather than just individual point-to-point exchanges. It is commonly used in parallel computing, distributed systems, and cluster computing to coordinate and manage the transmission, processing, and synchronization of data across multiple nodes.
1. Collective Communication Overview
- Broadcast
- Reduce
- AllReduce
- Gather
- AllGather
- Scatter
- ReduceScatter
- Barrier
Note: The root node acts as a server, serving as the target or source for certain operations.
Relationship: AllReduce = ReduceScatter + AllGather
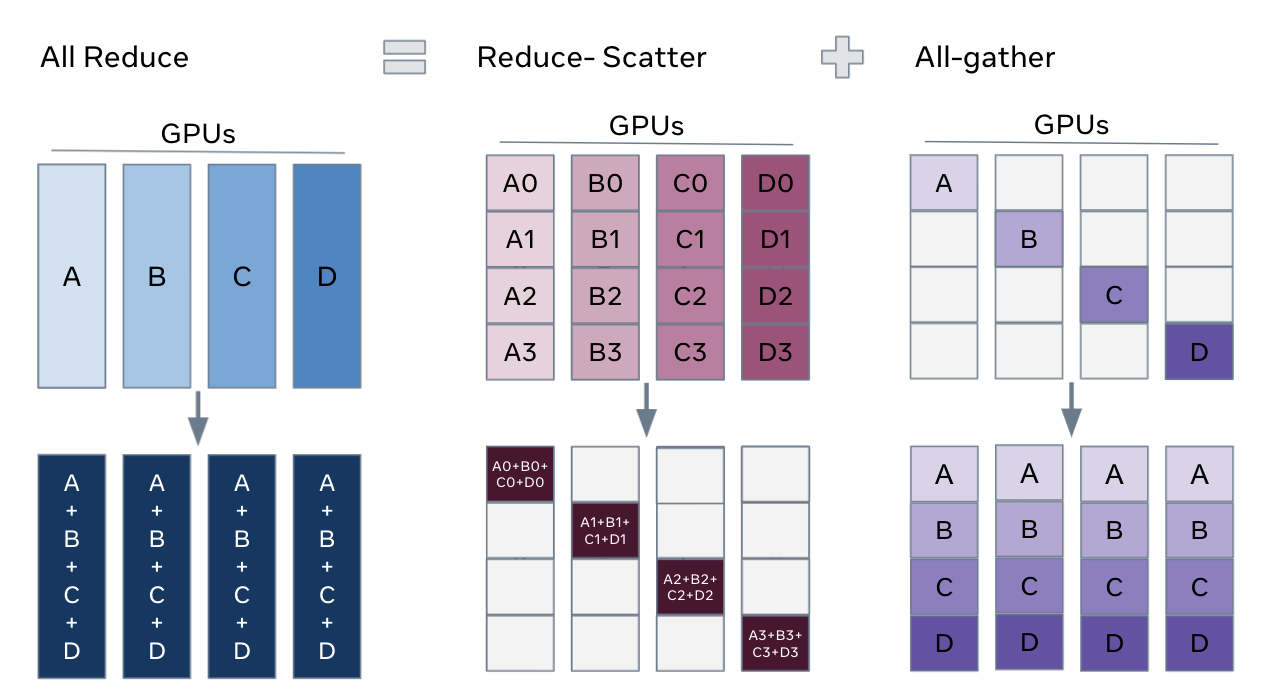
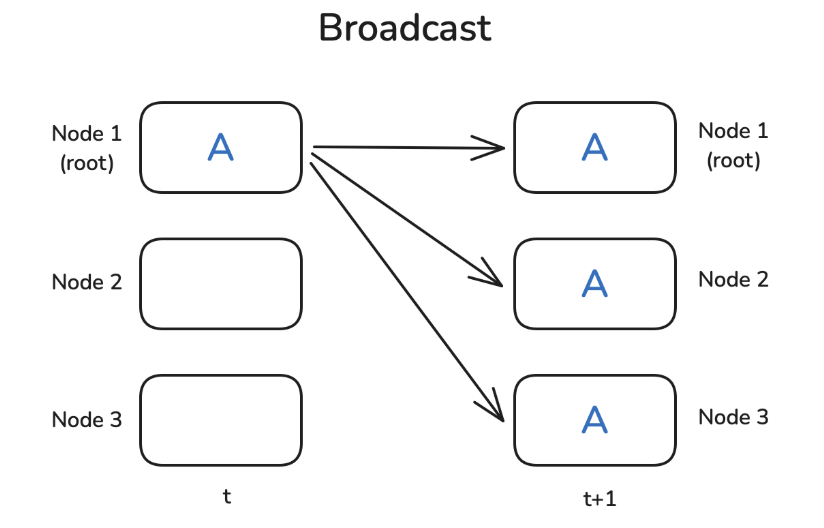
2. Broadcast
3. Reduce & AllReduce
Combine values from each node using a function to produce a single value.
Common functions for f() are SUM or AVG.
- AVG is only available with the NCCL backend.
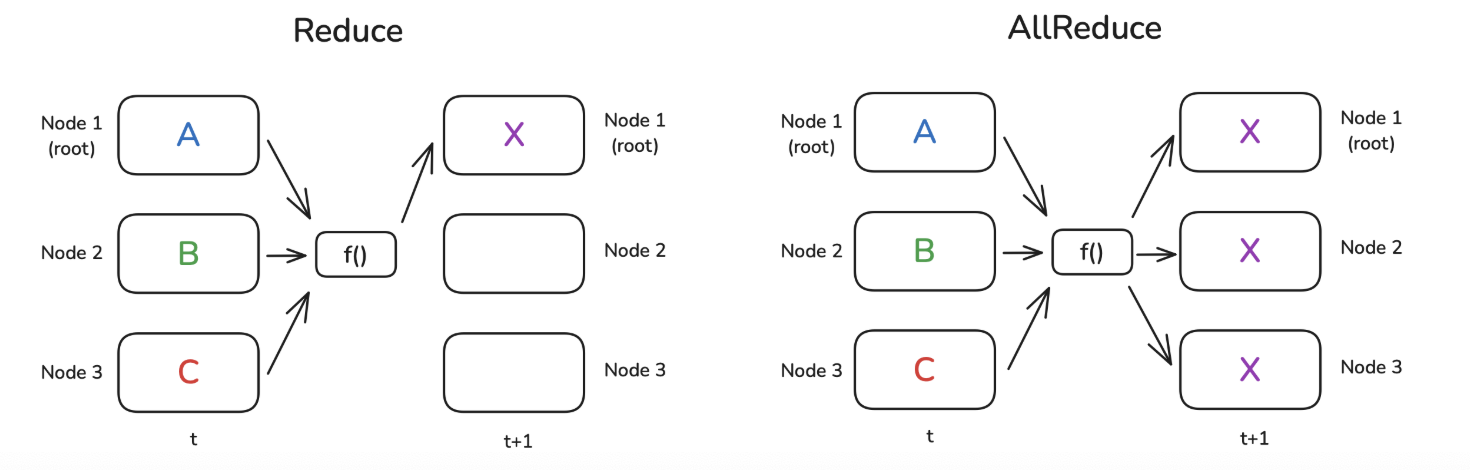
- Reduce: The result is sent only to the root node.
- AllReduce: The result is broadcast to every node (each node has the same value).
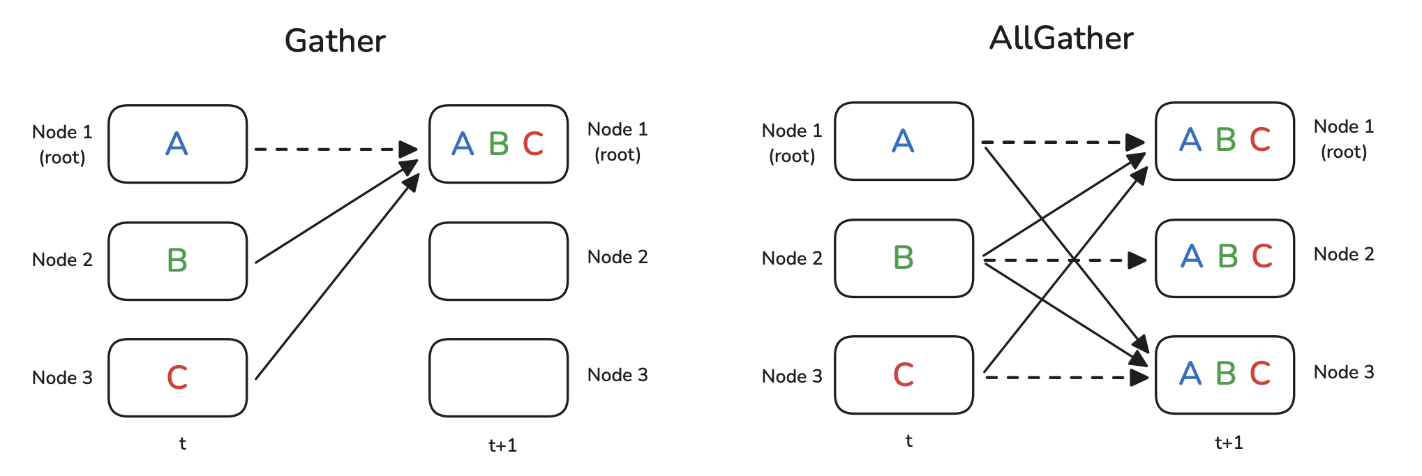
4. Gather & AllGather
5. Scatter & ReduceScatter
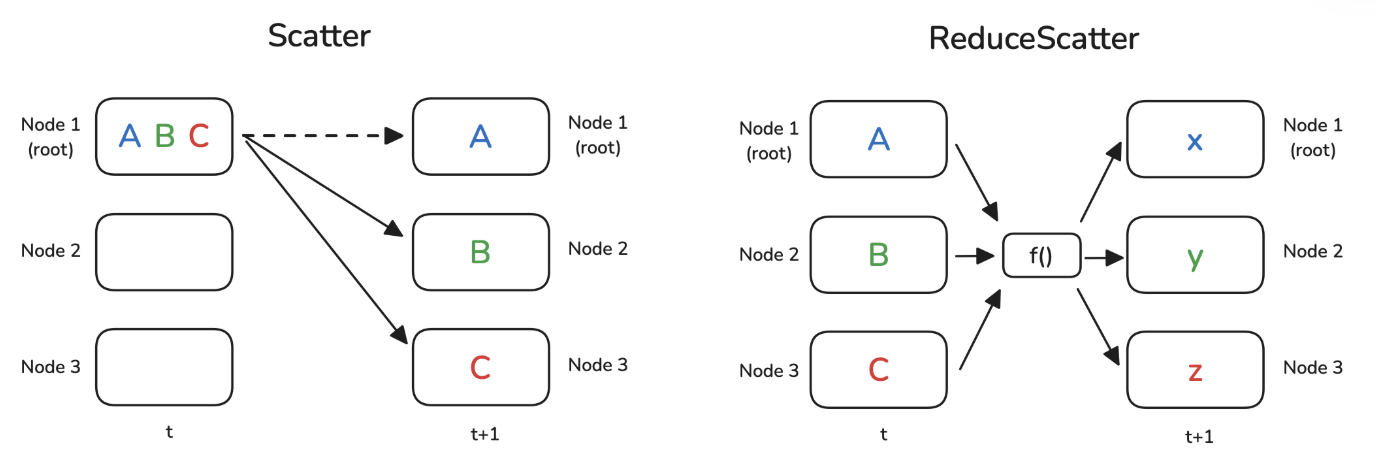 Scatter
Scatter
- Scatter differs from broadcast in that scatter sends data in pieces, while broadcast sends the entire data.
- Scatter is logically the reverse operation of gather.
ReduceScatter
- Split data on each node into pieces.
- Perform Reduce on data from each piece across nodes using a function.
- Scatter the result of each piece's Reduce to each node.
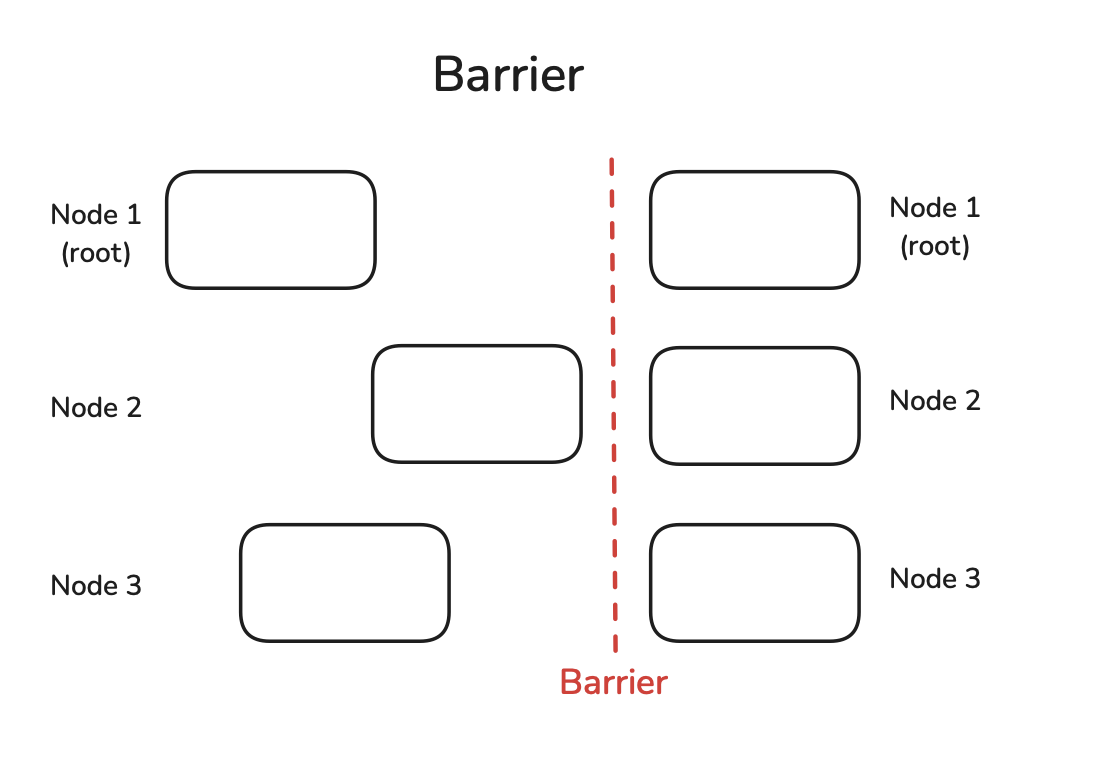
6. Barrier
A barrier will not be lifted until all nodes reach it. Once all nodes reach the barrier, subsequent computations can proceed, used for synchronizing nodes.
7. PyTorch Code Implementation
7.1. What is NCCL
NCCL
- NVIDIA Collective Communications Library
- Optimized primitives for communication between NVIDIA GPUs
- Designed for efficient GPU-GPU communication
7.2. Broadcast
Code
import torch
import torch.distributed as dist
def init_process():
dist.init_process_group(backend='nccl')
torch.cuda.set_device(dist.get_rank())
def example_broadcast():
if dist.get_rank() == 0:
tensor = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float32).cuda()
else:
tensor = torch.zeros(5, dtype=torch.float32).cuda()
print(f"Before broadcast on rank {dist.get_rank()}: {tensor}")
dist.broadcast(tensor, src=0)
print(f"After broadcast on rank {dist.get_rank()}: {tensor}")
init_process()
example_broadcast()
Output
Before broadcast on rank 0: tensor([1., 2., 3., 4., 5.], device='cuda:0')
Before broadcast on rank 1: tensor([0., 0., 0., 0., 0.], device='cuda:1')
Before broadcast on rank 2: tensor([0., 0., 0., 0., 0.], device='cuda:2')
After broadcast on rank 0: tensor([1., 2., 3., 4., 5.], device='cuda:0')
After broadcast on rank 1: tensor([1., 2., 3., 4., 5.], device='cuda:1')
After broadcast on rank 2: tensor([1., 2., 3., 4., 5.], device='cuda:2')
7.3. Reduce
Code
def example_reduce():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
print(f"Before reduce on rank {dist.get_rank()}: {tensor}")
dist.reduce(tensor, dst=0, op=dist.ReduceOp.SUM)
print(f"After reduce on rank {rank}: {tensor}")
init_process()
example_reduce()
Output
Before reduce on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
Before reduce on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
Before reduce on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
After reduce on rank 0: tensor([6., 6., 6., 6., 6.], device='cuda:0')
After reduce on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
After reduce on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
7.4. AllReduce
Code
def example_all_reduce():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
print(f"Before all_reduce on rank {dist.get_rank()}: {tensor}")
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"After all_reduce on rank {dist.get_rank()}: {tensor}")
init_process()
example_all_reduce()
Output
Before all_reduce on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
Before all_reduce on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
Before all_reduce on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
After all_reduce on rank 0: tensor([6., 6., 6., 6., 6.], device='cuda:0')
After all_reduce on rank 1: tensor([6., 6., 6., 6., 6.], device='cuda:1')
After all_reduce on rank 2: tensor([6., 6., 6., 6., 6.], device='cuda:2')
7.5. Gather
Code
def example_gather():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
if dist.get_rank() == 0:
gather_list = [
torch.zeros(5, dtype=torch.float32).cuda()
for _ in range(dist.get_world_size())
]
else:
gather_list = None
print(f"Before gather on rank {dist.get_rank()}: {tensor}")
dist.gather(tensor, gather_list, dst=0)
if dist.get_rank() == 0:
print(f"After gather on rank 0: {gather_list}")
init_process()
example_gather()
Output
Before gather on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
Before gather on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
Before gather on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
After gather on rank 0: [tensor([1., 1., 1., 1., 1.], device='cuda:0'),
tensor([2., 2., 2., 2., 2.], device='cuda:0'),
tensor([3., 3., 3., 3., 3.], device='cuda:0')]
7.6. AllGather
Code
def example_all_gather():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
gather_list = [
torch.zeros(5, dtype=torch.float32).cuda()
for _ in range(dist.get_world_size())
]
print(f"Before all_gather on rank {dist.get_rank()}: {tensor}")
dist.all_gather(gather_list, tensor)
print(f"After all_gather on rank {dist.get_rank()}: {gather_list}")
init_process()
example_all_gather()
Output
Before all_gather on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
Before all_gather on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
Before all_gather on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
After all_gather on rank 0: [tensor([1., 1., 1., 1., 1.], device='cuda:0'),
tensor([2., 2., 2., 2., 2.], device='cuda:0'),
tensor([3., 3., 3., 3., 3.], device='cuda:0')]
After all_gather on rank 1: [tensor([1., 1., 1., 1., 1.], device='cuda:1'),
tensor([2., 2., 2., 2., 2.], device='cuda:0'),
tensor([3., 3., 3., 3., 3.], device='cuda:0')]
After all_gather on rank 2: [tensor([1., 1., 1., 1., 1.], device='cuda:2'),
tensor([2., 2., 2., 2., 2.], device='cuda:2'),
tensor([3., 3., 3., 3., 3.], device='cuda:2')]
7.7. Scatter
Code
def example_scatter():
if dist.get_rank() == 0:
scatter_list = [
torch.tensor([i + 1] * 5, dtype=torch.float32).cuda()
for i in range(dist.get_world_size())
]
print(f"Rank 0: Tensor to scatter: {scatter_list}")
else:
scatter_list = None
tensor = torch.zeros(5, dtype=torch.float32).cuda()
print(f"Before scatter on rank {dist.get_rank()}: {tensor}")
dist.scatter(tensor, scatter_list, src=0)
print(f"After scatter on rank {dist.get_rank()}: {tensor}")
init_process()
example_scatter()
Output
Rank 0: Tensor to scatter: [tensor([1., 1., 1., 1., 1.], device='cuda:0'),
tensor([2., 2., 2., 2., 2.], device='cuda:0'),
tensor([3., 3., 3., 3., 3.], device='cuda:0')]
Before scatter on rank 0: tensor([0., 0., 0., 0., 0.], device='cuda:0')
Before scatter on rank 1: tensor([0., 0., 0., 0., 0.], device='cuda:1')
Before scatter on rank 2: tensor([0., 0., 0., 0., 0.], device='cuda:2')
After scatter on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
After scatter on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
After scatter on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
7.8. ReduceScatter
Code
def example_reduce_scatter():
rank = dist.get_rank()
world_size = dist.get_world_size()
input_tensor = [
torch.tensor([(rank + 1) * i for i in range(1, 3)], dtype=torch.float32).cuda()**(j+1)
for j in range(world_size)
]
output_tensor = torch.zeros(2, dtype=torch.float32).cuda()
print(f"Before ReduceScatter on rank {rank}: {input_tensor}")
dist.reduce_scatter(output_tensor, input_tensor, op=dist.ReduceOp.SUM)
print(f"After ReduceScatter on rank {rank}: {output_tensor}")
init_process()
example_reduce_scatter()
Output
Before ReduceScatter on rank 0: [tensor([1., 2.], device='cuda:0'),
tensor([1., 4.], device='cuda:0'),
tensor([1., 8.], device='cuda:0')]
Before ReduceScatter on rank 1: [tensor([2., 4.], device='cuda:1'),
tensor([ 4., 16.], device='cuda:1'),
tensor([ 8., 64.], device='cuda:1')]
Before ReduceScatter on rank 2: [tensor([3., 6.], device='cuda:2'),
tensor([ 9., 36.], device='cuda:2'),
tensor([ 27., 216.], device='cuda:2')]
After ReduceScatter on rank 0: tensor([ 6., 12.], device='cuda:0')
After ReduceScatter on rank 1: tensor([14., 56.], device='cuda:1')
After ReduceScatter on rank 2: tensor([ 36., 288.], device='cuda:2')
7.9. Barrier
Code
def example_barrier():
rank = dist.get_rank()
t_start = time.time()
print(f"Rank {rank} sleeps {rank} seconds.")
time.sleep(rank) # Simulate different processing times
dist.barrier()
print(f"Rank {rank} after barrier time delta: {time.time()-t_start:.4f}")
init_process()
example_barrier()
Output
Rank 0 sleeps 0 seconds.
Rank 1 sleeps 1 seconds.
Rank 2 sleeps 2 seconds.
Rank 0 after barrier time delta: 2.0025
Rank 1 after barrier time delta: 2.0025
Rank 2 after barrier time delta: 2.0024