
EasyR1 + Verl + Ray + QwenVL + GRPO
EasyR1 + Verl + Ray + QwenVL + GRPO
- Background Introduction
- GRPO Four Main Steps
- Implementation of GRPO Training Code Using EasyR1
- Practical Record of GRPO Training Details
1. Background Introduction
- EasyR1
- https://github.com/hiyouga/EasyR1
- Verl
- https://github.com/volcengine/verl
- Ray: Distributed Computing Framework
- https://segmentfault.com/a/1190000046195156
- GRPO
- Group Relative Policy Optimization
- grpo_trainer: https://huggingface.co/docs/trl/v0.16.1/grpo_trainer
- Experimental Records
- Model: QwenVL
- https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct
- Dataset: geometry3k
- https://huggingface.co/datasets/hiyouga/geometry3k
- Environment: One 8-card A800-80G
- Time Consumption: Training on geometry3k dataset (2.1k) for 15 episodes took a total of 8h20min
- Model: QwenVL
2. GRPO Four Main Steps
GRPO Four Main Steps
- Generating completions
- Computing the advantage
- Estimating the KL divergence
- Computing the loss
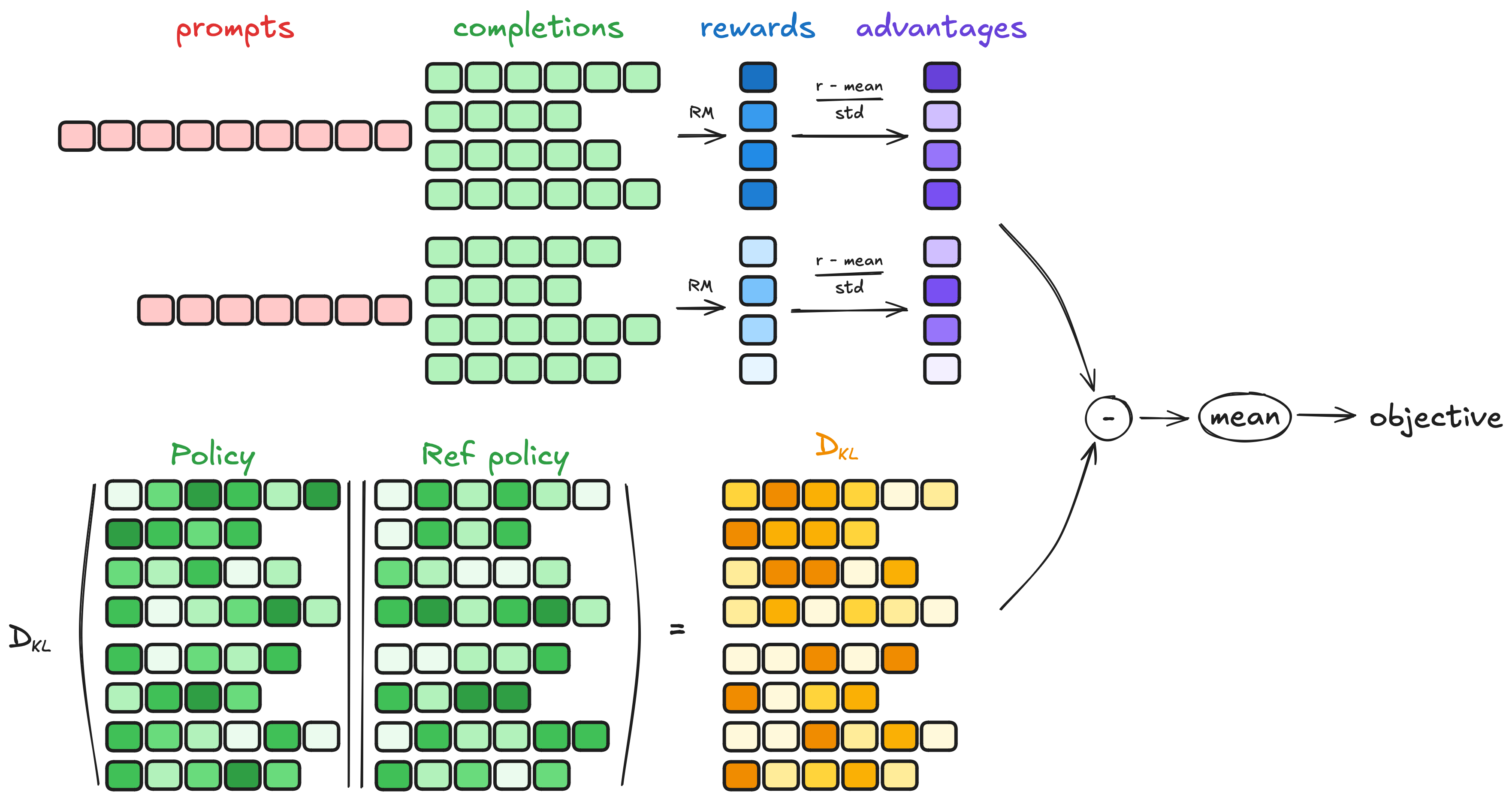
2.1. Generating Completions
In each training step, a batch of prompts is sampled, and a set of completion sequences (a group of G, each denoted as ) is generated for each prompt.
2.2. Computing the Advantage
For each of the G sequences in the group, rewards are calculated using the reward model. The advantage is computed through relative comparison and normalized as follows:
2.3. Estimating the KL Divergence
The KL divergence is estimated using the approximator introduced by Schulman et al. (2020). The approximator is defined as follows:
2.4. Computing the Loss
The goal is to maximize the advantage while ensuring that the model remains close to the reference policy. Therefore, the loss function is defined as follows:
Where the first term represents the scaled advantage, and the second term represents the penalty for deviating from the reference policy through KL divergence.
3. Implementation of GRPO Training Code Using EasyR1
3.1. GRPO Training: examples/qwen2_5_vl_3b_geo3k_grpo.sh
- Change comments to indicate modified areas
- If the command line
python3 -m verl.trainer.mainhas the same configuration items asexamples/config.yaml, the configurations here will override those inexamples/config.yaml
set -x
export VLLM_ATTENTION_BACKEND=XFORMERS # change
export VLLM_USE_V1=0 # change
RAY_PORT=6379 # change
DASHBOARD_PORT=8297 # change
MODEL_PATH=Qwen/Qwen2.5-VL-3B-Instruct # replace it with your local file path
SYSTEM_PROMPT="""You FIRST think about the reasoning process as an internal monologue and then provide the final answer.
The reasoning process MUST BE enclosed within <think> </think> tags. The final answer MUST BE put in \boxed{}."""
python3 -m verl.trainer.main \
config=examples/config.yaml \
data.train_files=hiyouga/geometry3k@train \
data.val_files=hiyouga/geometry3k@test \
data.system_prompt="${SYSTEM_PROMPT}" \
worker.actor.model.model_path=${MODEL_PATH} \
worker.rollout.tensor_parallel_size=1 \
trainer.experiment_name=qwen2_5_vl_3b_geo_grpo \
trainer.n_gpus_per_node=8
3.2. Configuration File: examples/config.yaml
- Change comments to indicate modified areas
data:
train_files: hiyouga/math12k@train
val_files: hiyouga/math12k@test
prompt_key: problem
answer_key: answer
image_key: images
max_prompt_length: 2048
max_response_length: 2096 # change
rollout_batch_size: 256 # change
val_batch_size: -1
shuffle: true
seed: 1
max_pixels: 2097152 # change
min_pixels: 262144
algorithm:
adv_estimator: grpo
disable_kl: false
use_kl_loss: true
kl_penalty: low_var_kl
kl_coef: 1.0e-2
worker:
actor:
global_batch_size: 64 # change
micro_batch_size_per_device_for_update: 2 # change
micro_batch_size_per_device_for_experience: 8 # change
max_grad_norm: 1.0
padding_free: true
ulysses_sequence_parallel_size: 1
model:
model_path: Qwen/Qwen2.5-7B-Instruct
enable_gradient_checkpointing: true
trust_remote_code: false
freeze_vision_tower: false
optim:
lr: 1.0e-6
weight_decay: 1.0e-2
strategy: adamw # {adamw, adamw_bf16}
lr_warmup_ratio: 0.0
fsdp:
enable_full_shard: true
enable_cpu_offload: false
enable_rank0_init: true
offload: # change
offload_params: false # true: more CPU memory; false: more GPU memory
offload_optimizer: false # true: more CPU memory; false: more GPU memory
rollout:
temperature: 1.0
n: 6 # change
gpu_memory_utilization: 0.7 # change
enforce_eager: false
enable_chunked_prefill: false
tensor_parallel_size: 2
limit_images: 1 # change
val_override_config:
temperature: 0.2 # change
n: 1
ref:
fsdp:
enable_full_shard: true
enable_cpu_offload: false # true: more CPU memory; false: more GPU memory # change
enable_rank0_init: true
offload:
offload_params: false
reward:
reward_type: function
compute_score: math
trainer:
total_episodes: 15 # change
logger: ["console", "wandb"]
project_name: easy_r1
experiment_name: qwen2_5_7b_math_grpo
n_gpus_per_node: 8
nnodes: 1
val_freq: 5 # -1 to disable
val_before_train: true
val_only: false
val_generations_to_log: 1 # change
save_freq: 5 # -1 to disable
save_limit: 3 # -1 to disable
save_checkpoint_path: null
load_checkpoint_path: null
3.3. Entry Point: verl.trainer.main.py
- Merge configurations
- First, merge the default configuration with the configuration from the file
- Then, merge the previously merged configuration with the configuration from the command line
- Initialize ray (if ray is not initialized)
- ray.init(runtime_env={"env_vars": {"TOKENIZERS_PARALLELISM": "true", "NCCL_DEBUG": "WARN"}})
- Let ray execute runner.run
- ray.get(runner.run.remote(ppo_config))
- Instantiate trainer and execute training
trainer = RayPPOTrainer(
config=config,
tokenizer=tokenizer,
processor=processor,
role_worker_mapping=role_worker_mapping,
resource_pool_manager=resource_pool_manager,
ray_worker_group_cls=ray_worker_group_cls,
reward_fn=reward_fn,
val_reward_fn=val_reward_fn,
)
trainer.init_workers() # Init resource pool and worker group
trainer.fit() # The training loop of PPO
3.4. trainer.fit()
class RayPPOTrainer:
def fit(self):
for _ in tqdm(range(self.config.trainer.total_episodes), desc="Episode", position=0):
for batch_dict in tqdm(self.train_dataloader, desc="Running step", position=1):
# generate sequences
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
# compute reward
reward_tensor, reward_metrics = self.reward_fn(batch)
batch.batch["token_level_scores"] = reward_tensor
reward_metrics = {f"reward/{key}": value for key, value in reduce_metrics(reward_metrics).items()}
# recompute old_log_probs
old_log_probs = self.actor_rollout_wg.compute_log_probs(batch)
# compute ref_log_probs
ref_log_probs = self.ref_policy_wg.compute_ref_log_probs(batch)
batch.batch["token_level_rewards"] = batch.batch["token_level_scores"]
# compute advantages
batch = compute_advantage(
batch,
adv_estimator=self.config.algorithm.adv_estimator,
gamma=self.config.algorithm.gamma,
lam=self.config.algorithm.lam,
)
# update actor
actor_output = self.actor_rollout_wg.update_actor(batch)
4. Practical Record of GRPO Training Details
4.1. Key Data Information
- train_dataset: 2100 (2100 training data entries)
- val_dataset: 300 (300 validation data entries)
- max_prompt_len: 2048 (Maximum length of Prompt is 2048 tokens)
- max_resp_len: 2096 (Maximum length of Completion is 2096 tokens)
- max_total_len: 4144 (Total maximum length of Prompt and Completion is 4144 tokens)
- (max_total_len = max_prompt_len + max_resp_len = 2048 + 2096 = 4144)
- total_episodes: 15 (Total number of epochs is 15)
- rollout_batch_size: 256 (256 entries as one rollout batch)
- rollout_n: 6 (Each entry generates 6 sequences)
- rollout_batch_size * rollout_n = 256 * 6 = 1536 (One rollout batch processes 1536 sequences)
- nnodes: 1 (Number of nodes is 1)
- n_gpus_per_node: 8 (Number of GPUs per node is 8)
- world_size = nnodes * n_gpus_per_node = 1 * 8 = 8 (Concurrency world_size is 8)
- (rollout_batch_size * rollout_n) / (nnodes * n_gpus_per_node) = 256 * 6 / 8 = 192 (Each GPU processes 192 token sequences)
- global_batch_size: 64 (Global batch size is 64, meaning 64 sequences are updated at once)
- global_batch_size_per_device = global_batch_size * rollout_n / world_size = 64 * 6 / 8 = 48 (Global batch size per GPU)
- mini_batches = nums_per_rank / global_batch_size_per_device = 192/ 48 = 4 (Each rollout batch is processed in 4 updates)
- micro_batch_size_per_device_for_experience: 8 (Each GPU's processing micro-batch is 8)
- micro_batch_size_per_device_for_update: 2 (Each GPU's update micro-batch is 2)
4.2. Training Details
- episodes 15 (15 epochs)
- steps 8 (train_dataset / rollout_batch_size = 2100 / 256 = 8) (Each 256 entries of the dataset as one rollout batch, each epoch is divided into 8 steps)
- batch_dict
- batch_dict.keys(): ['input_ids', 'attention_mask', 'position_ids', 'problem', 'id', 'choices', 'ground_truth', 'multi_modal_data', 'multi_modal_inputs', 'raw_prompt_ids']
- batch_dict['input_ids'].shape: (rollout_batch_size, max_prompt_len)
- [256, 2048]
- nums_per_step 1536 (rollout_batch_size * rollout_n = 256 * 6 = 1536) (One rollout batch has 256 entries, each entry generates 6 sequences, a total of 1536 token sequences to be processed)
- nums_per_rank 192 (rollout_batch_size * rollout_n / world_size = 1536 / 8 = 192) (With 8 GPUs, each GPU processes 192 token sequences)
- generate sequences
- compute reward
- reward_tensor, reward_metrics = self.reward_fn(batch)
- batch.batch["token_level_scores"] = reward_tensor # Each token's score, (each token corresponds to a score, the token at boxed{x} as the answer has a score greater than 0, others equal to 0)
- reward_metrics: {'reward/overall': x1, 'reward/format': x2, 'reward/accuracy': x3}
- Compute log probs
- 24 (nums_per_rank / micro_batch_size_per_device_for_experience = 192 / 8 = 24) Calculate the probability estimates for each completion token sequence, each token corresponds to a probability, with 2096 dimensions (Each GPU's processing micro-batch is 8, processed 24 times)
- compute old_log_probs & compute ref_log_probs
- compute old_log_probs Calculate the log_probs of the old actor model (not yet updated in this batch)
- compute ref_log_probs Calculate the log_probs of the ref model
- Aggregate log prob
- [1536, 2096] (Aggregate log prob data of the rollout batch)
- compute advantage Calculate the advantage
- Calculate the score for each completion token sequence
- [1536]
- scores = token_level_scores.sum(-1) The sum of scores for each token is the final score
- Calculate the mean and standard deviation for each group
- id2mean, id2std
- rollout_n's uids are the same, used to calculate mean and standard deviation
- Calculate relative advantage within the group
- [1536]
- scores[i] = (scores[i] - id2mean[index[i]]) / (id2std[index[i]] + eps)
- [1536,2096] 2096 dimensions of values are the same, all are the relative advantage calculated within the group
- update actor (actor model == policy model)
- Calculate mini_batches (if rollout_batch_size==global_batch_size, mini_batches is 1)
- nums_per_rank 192
- global_batch_size 64
- global_batch_size_per_device = global_batch_size * rollout_n / world_size = 64 * 6 / 8 = 48
- mini_batches = nums_per_rank / global_batch_size_per_device = 192 / 48 = 4
- Train mini batch (4)
- One mini_batch updates parameters once
- Each mini_batch processes 48 entries per GPU, each micro_batch is 2 for backpropagation to calculate gradients, performed 24 times of gradient accumulation
- gradient_accumulation 24
- gradient_accumulation = global_batch_size_per_device / micro_batch_size_per_device_for_update = 48 / 2 = 24