
GRPO + Unsloth + vLLM
GRPO + Unsloth + vLLM
- GRPO工作原理
- GRPO vs PPO
- GRPO的三个革命性设计
- GRPO 代码实现
- GRPO (Group Relative Policy Optimization,群体相对策略优化) :是一种强化学习方法,专注于根据特定的奖励函数优化模型的性能
- Unsloth:用于高效微调大语言模型的框架
- vllm:针对大语言模型优化的推理框架
1. GRPO
GRPO (Group Relative Policy Optimization,群体相对策略优化)
GRPO首次在2024年2月至2024年4月的DeepSeek’s Math paper中引入,随后DeepSeek在创建DeepSeek R1时利用了GRPO算法,如他们的论文所述。
1.1. GRPO能做什么
利用GRPO可以将标准模型转化为功能完备的推理模型。
GRPO的主要目标是最大化奖励并学习答案是如何推导出来的,而不是简单地记忆和复现训练数据中的回答。
常规的微调(不使用GRPO)仅最大化下一个单词的预测概率,但不会针对奖励进行优化。GRPO则是优化奖励函数,而不仅仅是预测下一个单词。
最初,人们需要收集大量数据来填充推理过程或思维链。但 GRPO或其他强化学习算法能够引导模型自动展现推理能力并生成推理轨迹,这依赖于GRPO或其他强化学习算法创建良好的奖励函数或验证器。
GRPO的应用场景不仅限于代码或数学领域,其推理过程还能增强诸如邮件自动化、数据库检索、法律和医疗等任务,基于训练采用的数据集和奖励函数,极大提升准确性!
1.2. GRPO工作原理
- 对于每个问答对,模型生成多个响应作为一组(例如,8个不同的响应)
- 为每个响应根据奖励函数进行打分
- 计算该组响应的平均得分作为基准线
- 每个响应的得分与平均得分比较,每个响应的优势值由其得分与基准线的差值决定
- 模型被增强以倾向于得分更高的响应
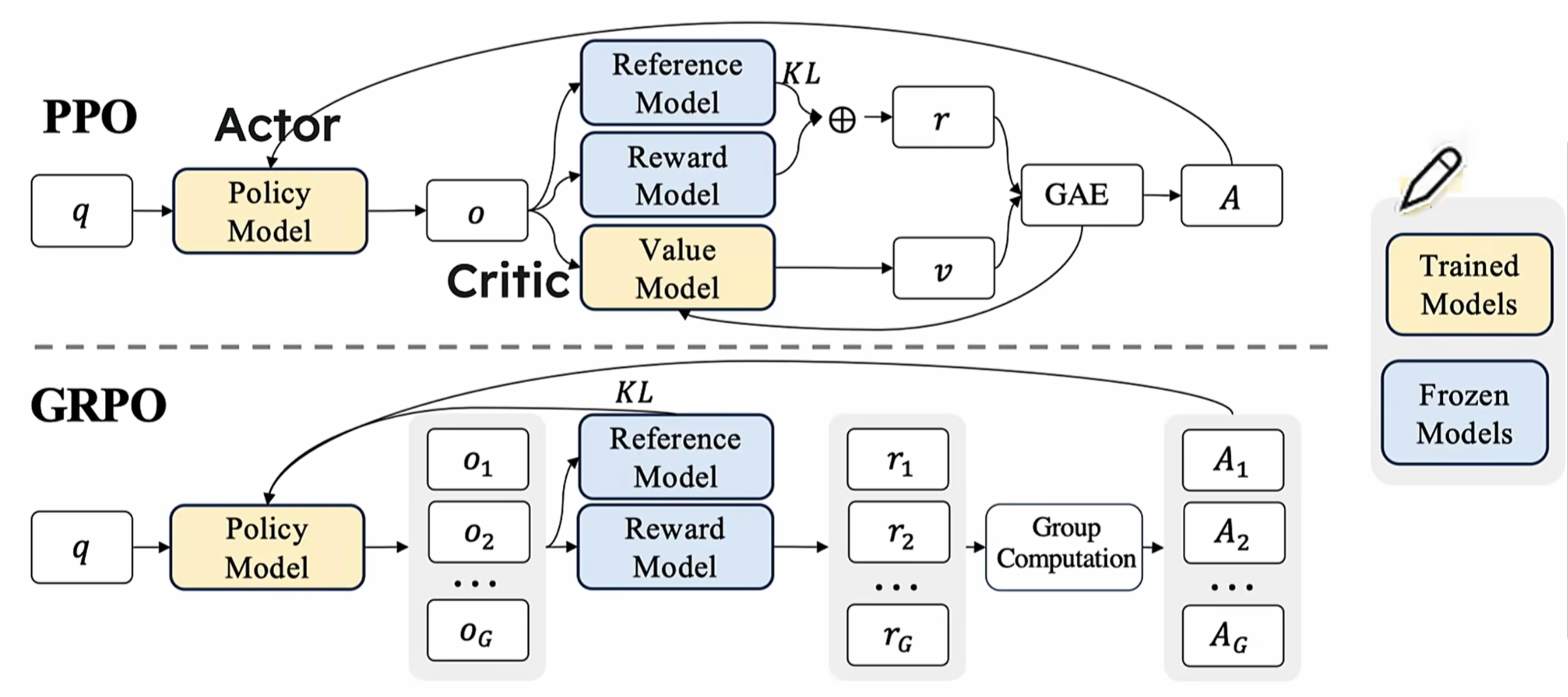
1.3. GRPO vs PPO
1.3.1. PPO的"双师困境"
传统强化学习方法中,PPO(Proximal Policy Optimization,近端策略优化)被广泛应用,其训练系统需要两个"老师"协同工作:策略模型(学生)负责生成答案,价值模型(评分老师)负责评估质量。这种架构存在三个根本性缺陷:
- 资源消耗黑洞:价值模型的参数量往往与策略模型相当,训练时需要额外存储梯度参数,显存占用翻倍
- 评估标准偏移:两个模型的异步更新容易导致"教学标准"不一致
- 绝对评分陷阱:单个输出的绝对评分难以反映答案间的相对优劣 这些问题在复杂推理任务中尤为突出。当处理多步数学证明时,传统方法就像用同一把尺子丈量不同维度的答案,容易产生评估偏差。
1.3.2. GRPO对PPO的改进
想象一下,你在教一个学生解决数学题。传统方法可能需要另一位老师(价值函数模型)来评估学生的表现。而GRPO采用了一种更智能的方式:让学生生成多个答案,然后通过比较这些答案的优劣来指导学习。这种方法不仅更加直观,还大大提高了学习效率。更贴近人类"比较学习"的认知方式,答案的优劣不再由绝对分数决定,而是通过群体比较产生。
GRPO是在广受欢迎的PPO(Proximal Policy Optimization)基础上发展而来的强化学习方法。它最大的创新在于引入了"组内相对评估"机制,同时去除了传统方法中需要的价值函数模型,使整个训练过程更加高效和稳定。
1.4. GRPO的三个革命性设计
1.4.1. 从绝对评估机制转为相对评估机制
这种相对评估机制带来了三大优势:
- 评估维度归一化:自动消除题目难易度差异的影响
- 误差补偿效应:随机波动在群体比较中被自然平滑
- 隐性知识挖掘:模型通过对比学习到评分标准之外的隐性规律
1.4.2. 去除了价值函数模型
- GRPO的成功验证了"少即是多"的技术哲学。
- GRPO这种强化学习技术无需价值函数模型即可高效优化响应,与PPO相比,降低了内存和计算成本。
- 通过简单的矩阵运算替代复杂模型推理,训练速度提升40%,显存占用降低55%。这种设计尤其适合当今千亿参数大模型的训练需求
# 传统PPO优势计算
advantage = reward - value_model.predict(state)
# GRPO优势计算
group_rewards = [r1, r2, ..., rn]
baseline = np.mean(group_rewards)
advantages = [r - baseline for r in group_rewards]
在GSM8K数学基准测试中,GRPO加持的模型展现出惊人的突破:

1.4.3. KL智能约束
GRPO将KL散度约束直接融入损失函数,创造性地解决了强化学习的"灾难性遗忘"难题
Loss = -E[log(π(a|s)) * A] + β*KL(π||π_ref)
其中β参数通过自适应算法动态调整,在探索与收敛之间实现微妙平衡。实验显示,这种设计使数学推理任务的训练稳定性提升70%。
1.5. LLM不同训练方式比较
- SFT
- 规范模型输出格式(带上reasoning和answer标签)
- 很难学到数据背后的数学规律和元思维,还是只能学到next token的生成概率
- 泛化能力差,有点死记硬背
- 传统RL
- 大量包含解题步骤的高质量数据和精确的reward function,然后大力出奇迹训练
- 有long-cot,属于是有标准答案的这种,所以model完全按照long-cot去拟合靠拢,本质是按照训练数据的标准答案、解题过程去学
- 没有多个答案之间互相对比(没有答案的优劣区分),有点像填鸭式的应试教育
- GRPO
- 通过试错和尝试,鼓励模型在最大化奖励过程中学到推理背后的规律
- GRPO只看结果,过程由模型自己摸索和尝试。没有标准的cot答案(只有最终的答案), 需要model自己做大量探索,找到最优cot,所以model有aha moment,泛化性好一些
- reward灵活,每个问题生成多个responce,找到最优的几个,引导model向最优的方向靠拢
- 这样做前期100多step输出的reason格式很混乱,所以R1在R1-zero的基础上先用long-cot做SFT,让model的responce先按照既定的template输出,适当减少一些探索的step,提升train效率
- 泛化性和推理表现上界更高
2. Unsloth高效GRPO训练
- 借助15GB的显存,Unsloth能够将任何高达17B参数的模型,如Llama 3.1(8B)、Phi-4(14B)、Mistral(7B)或Qwen2.5(7B),转化为推理模型。
- 极限情况下只需要 5G 显存,即可在本地训练自己的推理模型,达到“顿悟”时刻(适用于任何1.5B参数或更少的模型)。
- 此前,GRPO 仅支持全量微调,Unsloth AI 使其能够与 QLoRA 和 LoRA 兼容
- Unsloth x vLLM:vLLM实现快速推理,可以提高吞吐量(能提升 20 倍),可以允许微调和推理同时进行,还神奇地消除了同时加载vLLM和Unsloth时的双倍内存消耗
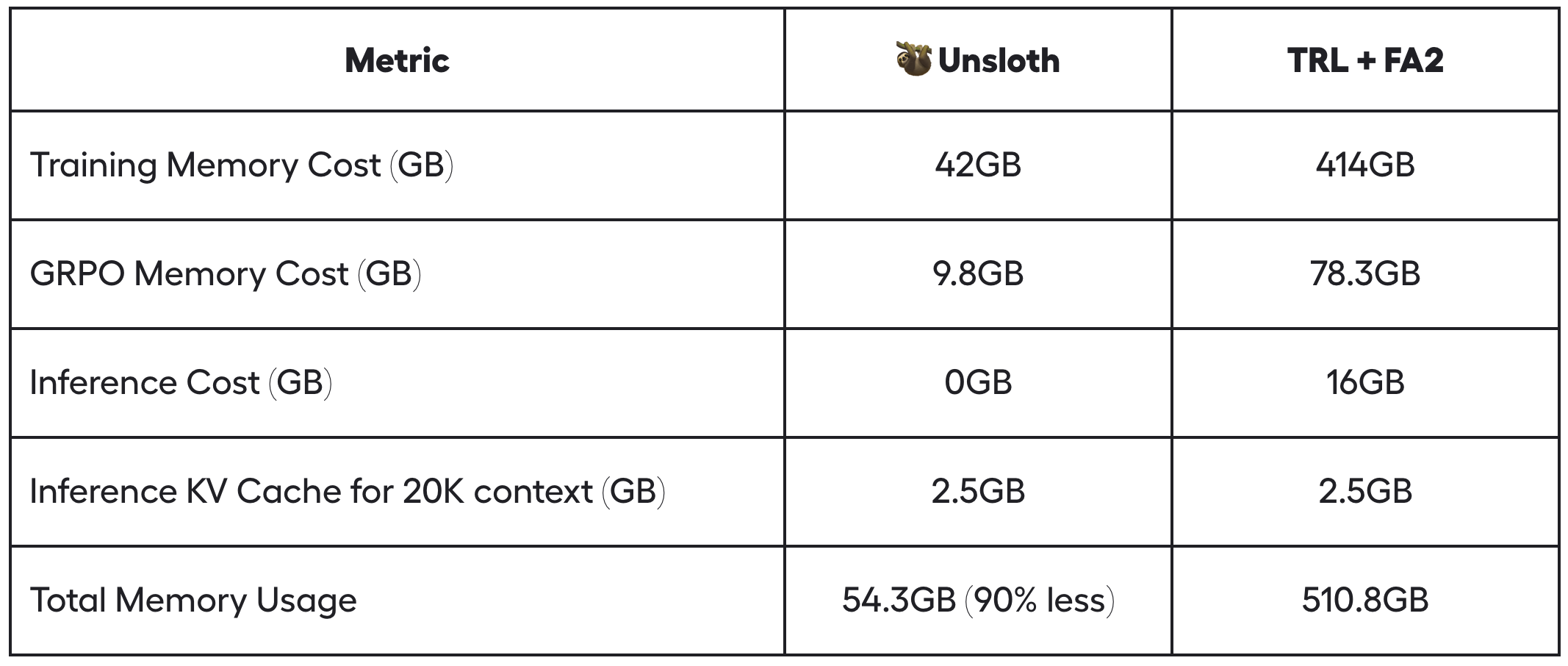
- Unsloth通过多种技巧巧妙地减少了 90% 以上的显存使用量,相比标准实现(HuggingFace TRL + Flash Attention 2)大幅优化。例如,在 20K 上下文长度下,每个提示生成 8 次,Unsloth 对 Llama 3.1 8B 仅使用 54.3GB 显存,而标准实现需要 510.8GB(Unsloth 节省了 90% 的显存)
- Unsloth针对GRPO的新内存高效线性内核将内存使用量减少了 8 倍或更多。这削减了 68.5GB 的内存,同时借助 torch.compile 实现 num_generations = 8 和 20K 上下文长度,速度实际上更快。
- Unsloth利用智能 Unsloth 梯度检查点算法,智能地将中间激活异步卸载到系统内存中,同时仅减慢 1% 的速度。由于我们需要 num_generations = 8,因此可以节省高达 372GB 的 VRAM。我们可以通过中间梯度累积进一步减少这种内存使用量。
- Unsloth 还使用与底层推理引擎(vLLM)相同的 GPU/CUDA 内存空间,与其他包的实现不同,这削减了 16GB 的显存。
3. GRPO训练经验之谈
- 至少等待 300 steps 才能看到奖励实质性的增长
- 至少 500 rows 数据去训练模型
- 应用GRPO的标准模型至少1.5B参数以生成思维链,太小的模型可能无法生成思维链
- 对于GRPO在QLoRA 4-bit模式下的GPU显存需求,一般规则是模型参数量等于所需的显存量。
- 设置的上下文长度越长,所需的显存越多。而LoRA 16-bit至少会使用4倍以上的显存。
- GRPO的一大优点是您甚至不需要大量数据。您只需要一个优秀的奖励函数/验证器,并且训练时间越长,模型就会变得越好。奖励值会随着训练步数的增加而提升。
- 奖励函数和验证器
- 奖励函数:进行打分
- 验证正确性不是必须的
- 奖励函数可以使用验证器
- 验证器:验证正确性
- 不进行打分
- 验证器也可以执行代码来验证逻辑或语法和其他正确性
- 奖励函数:进行打分
- 设计奖励函数或验证器没有唯一正确的方法——可能性是无限的。然而,它们必须设计得当且有意义,因为设计不当的奖励可能会无意中降低模型性能。
4. 代码实现
4.1. 安装需要的库
%%capture # Jupyter 的魔法命令,用来捕获单元格的输出,从而避免显示冗长的安装过程
import sys; modules = list(sys.modules.keys()) # 获取当前已加载的所有模块名
for x in modules: sys.modules.pop(x) if "PIL" in x or "google" in x else None # 移除PIL(Pillow)和google相关模块的缓存
!pip install unsloth vllm # 安装unsloth和vllm
!pip install --upgrade pillow # 升级pillow
4.2. 加载Llama-3.1-8B-Instruct模型
# 导入核心库
from unsloth import FastLanguageModel # 高效加载模型的库
import torch # PyTorch 深度学习框架
# 模型配置参数
max_seq_length = 1024 # 最大输入序列长度(影响显存占用)
lora_rank = 32 # LoRA的秩,越大的值,模型能力越强,但也会越慢
# 加载基础模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "meta-llama/meta-Llama-3.1-8B-Instruct", # 基础模型为 8B 参数的 Llama3 指令微调版
max_seq_length = max_seq_length,
load_in_4bit = True, # 为True则使用4bit量化(显存优化),为False则使用16bit
fast_inference = True, # 启用 vLLM 加速推理
max_lora_rank = lora_rank, # LoRA 最大秩限制
gpu_memory_utilization = 0.6, # GPU 显存利用率(如果OOM可调低)
)
4.3. GRPO训练前的推理
# 创建聊天模板
text = tokenizer.apply_chat_template([
{"role" : "user", "content" : "Calculate pi."},
],
tokenize = False, # 表示不对输入进行分词
add_generation_prompt = True)
# 设置采样参数
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024, # 生成文本的最大长度
)
# 生成文本
output = model.fast_generate(
[text],
sampling_params = sampling_params,
lora_request = None, # 表示不使用 LoRA(低秩适应)请求
)[0].outputs[0].text
output
4.4. 加载并准备数据集
OpenAI的GSM8K数据集
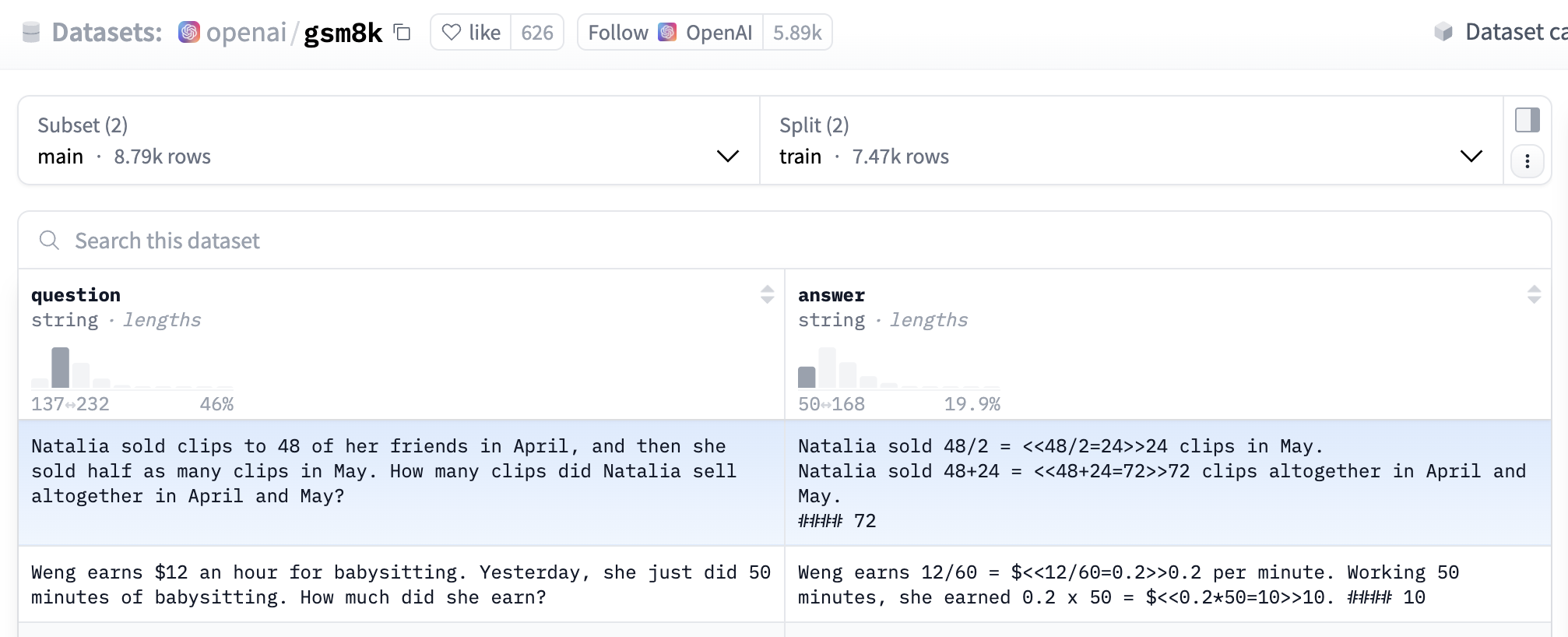
import re # 正则表达式
from datasets import load_dataset, Dataset
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip()
# uncomment middle messages for 1-shot prompting
def get_gsm8k_questions(split = "train") -> Dataset:
data = load_dataset('openai/gsm8k', 'main')[split] # 加载数据集
data = data.map(lambda x: { # 构造为dict格式
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
}) # type: ignore
return data # type: ignore
dataset = get_gsm8k_questions()
4.5. 设置 LoRA 微调配置
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank,
target_modules = [ # 应用 LoRA 的模块 (如果OOM可去掉QKVO)
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = lora_rank, # LoRA 缩放因子,,通常与秩相同,用于调整 LoRA 的影响
use_gradient_checkpointing = "unsloth", # 应用激活值重新计算/梯度检查点,以适用于长文本微调,设为"unsloth",可能指使用库特定的梯度检查点实现(显存优化技术)
random_state = 3407, # 随机种子(保证实验可复现)
)
4.6. 定义奖励函数
# LLM生成答案与标准答案一致则进行奖励
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions] # LLM生成的结果列表
q = prompts[0][-1]['content'] # 问题
extracted_responses = [extract_xml_answer(r) for r in responses] # LLM生成的答案列表
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)] # 将LLM生成的每个答案与标准答案对比
# LLM生成答案为数字则进行奖励
def int_reward_func(completions, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
# LLM生成结果符合system prompt的格式要求则进行奖励(严格版本)
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
# LLM生成结果符合system prompt的格式要求则进行奖励(宽松版本)
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
# LLM生成结果符合system prompt的格式要求则进行奖励(按点给奖励),并在 <answer> 和 </answer> 标签之间的内容长度越短,奖励越高
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
def count_xml(text) -> float:
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
4.7. 配置GRPO参数
max_prompt_length = 256 # 模型输入的最大提示长度
from trl import GRPOConfig, GRPOTrainer
training_args = GRPOConfig(
learning_rate = 5e-6, # 学习率,优化器在每次更新时调整模型参数的步长
adam_beta1 = 0.9, # Adam 优化器的 beta 参数,用于控制动量的计算
adam_beta2 = 0.99, # Adam 优化器的 beta 参数,用于控制动量的计算
weight_decay = 0.1, # 权重衰减,用于防止过拟合,通过在每次更新时减少权重的大小来实现
warmup_ratio = 0.1, # 学习率预热比例,表示在训练开始时,学习率会逐渐增加到设定的学习率
lr_scheduler_type = "cosine", # 学习率调度器类型,设为 "cosine",表示学习率会按照余弦函数的方式逐渐减少
optim = "paged_adamw_8bit", # 优化器,"paged_adamw_8bit"是一种优化器的变体,可能用于减少内存占用
logging_steps = 1, # 设置日志记录的步数为 1,表示每一步都记录日志
per_device_train_batch_size = 1, # 设置每个设备的训练批次大小为 1
gradient_accumulation_steps = 1, # 梯度累积步数,可以增加到4,以便更平滑的训练
num_generations = 6, # 生成的数量(如果OOM则可以减小该值)
max_prompt_length = max_prompt_length,
max_completion_length = max_seq_length - max_prompt_length, # 最大补全长度,确保生成的文本不会超过模型的最大序列长度
# num_train_epochs = 1, # Set to 1 for a full training run
max_steps = 250, # 最大训练步数
save_steps = 250, # 保存模型的步数,表示每 250 步保存一次模型
max_grad_norm = 0.1, # 最大梯度范数,用于梯度裁剪以防止梯度爆炸
report_to = "none", # Can use Weights & Biases
output_dir = "outputs", # 输出目录,用于存储训练结果和模型检查点
)
4.8. 定义GRPOTrainer
trainer = GRPOTrainer(
model = model, # 基础模型
processing_class = tokenizer, # embedding模型
reward_funcs = [ # 奖励函数
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func,
],
args = training_args, # 训练参数
train_dataset = dataset, # 数据集
)
4.9. 开始GRPO训练
trainer.train()
4.10. 保存LoRA权重
model.save_lora("grpo_saved_lora") # 保存LoRA权重到grpo_saved_lora文件
4.11. GRPO训练后的推理
text = tokenizer.apply_chat_template([
{"role" : "system", "content" : SYSTEM_PROMPT}, # 与训练前推理不同点1: 添加了system prompt
{"role" : "user", "content" : "Calculate pi."},
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
text,
sampling_params = sampling_params,
lora_request = model.load_lora("grpo_saved_lora"), # 与训练前推理不同点2: 加载LoRA权重
)[0].outputs[0].text
output
5. 参考
https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-GRPO.ipynb
https://www.kaggle.com/code/kingabzpro/fine-tuning-deepseek-r1-reasoning-model
https://colab.research.google.com/github/wandb/examples/blob/master/colabs/intro/Intro_to_Weights_%26_Biases.ipynb
https://www.51cto.com/aigc/4216.html
https://unsloth.ai/blog/grpo