
Fine-tuning
Fine-tuning
- Model Fine-tuning Process
- LoRA & QLoRA
- MoE: Mixture of Experts Model
- RLHF: Reinforcement Learning from Human Feedback
1. Fine-tuning
- Goal: Amplify required abilities while keeping others unchanged
- Update Knowledge: Introduce new domain-specific information
- Customize Behavior: Adjust the model’s tone, personality, or response style
- Optimize for Tasks: Improve accuracy and relevance for specific use cases
- Value: Enhances corresponding capabilities
- Issue: Catastrophic Forgetting (risk of degradation in other abilities)
- Solutions:
- Solution 1: No need to solve
- If other abilities are not crucial, degradation might not matter much
- Solution 2: Use larger models, as they are less likely to be affected due to better generalization ability
- Solution 3: Multi-task fine-tuning
- Combine data from multiple tasks
- Fill in the abilities where lacking
- Solution 1: No need to solve
- Solutions:
1.1. Instruction Fine-tuning / Supervised Fine-tuning
- FT (Fine-tuning)
- SFT (Supervised Fine-tuning), also known as Instruction Fine-tuning
- Fine-tuning the model with explicit instructions or examples for specific tasks, typically preserving the knowledge of the pre-trained model
- Advantages: Focuses on fine-tuning for specific tasks with high adaptability, while retaining the model's basic capabilities.
- Disadvantages: May not fully explore the model’s potential for highly complex tasks.
1.2. Multi-task Fine-tuning
Enhancing multiple abilities by combining data from various tasks into one training set.

2. Model Fine-tuning Process
- Define the problem
- Try Prompt Engineering to see if it solves the issue
- Use Few-shot if possible; if not, consider Fine-tuning. Fine-tuned models improve in the targeted area but may degrade in others.
- Few-shot
- Issues:
- Token count increases, context fills up quickly
- Adding multiple few-shot examples still doesn’t improve performance
- Issues:
- If unsuccessful, proceed with Fine-tuning
- Select multiple open-source models for experimentation
- Analyze the gap between actual and expected performance, identify missing capabilities
- Choose model:
- Fine-tuned Model
- Collect data
- Clean the data
- Instruction Fine-tuning (SFT)
- Alignment
- Evaluate
- A/B Testing
- Compression/Quantization & Deployment
- RLHF (Reinforcement Learning from Human Feedback)
3. Data Construction
Data format is different from traditional AI, using question-answer pairs (input, output), where the input part is a prompt form (because users will interact with prompts).
- Input: Prompt = Instruction + input
- Output: output
JSON format:
{
"instruction": "xxx",
"input": "", // Sometimes empty, sometimes with value
"output": "xxx"
}
Not much data is needed, around 1000 entries are sufficient (typically a few thousand to tens of thousands), since you are adding functionality to an existing model rather than training from scratch.
Fine-tuning process—split data into training, validation, and test sets:
- Training set: Data used for training
- Validation set: Used to check performance during training (e.g., mock exams)
- Test set: Final evaluation after training (e.g., final exam)
4. Fine-tuning Strategies
4.1. Based on Fine-tuning Scope: Full and Partial Parameter Fine-tuning
- Full Fine-tuning
- All parameters are adjusted, which has a significant impact and may affect previous capabilities. Not recommended.
- Advantages: Highly tailored to specific tasks, can significantly improve model performance
- Disadvantages: Requires a lot of computational resources and time, may reduce generalization on other tasks
- Partial Fine-tuning / Freeze Fine-tuning
- Only a subset of the model’s parameters (e.g., later layers or specific layers) is fine-tuned, not all parameters.
- Advantages: Lower resource demands, smaller risk of overfitting
- Disadvantages: May not adapt as well to complex tasks as full fine-tuning
- Sub-categories:
- PEFT (Parameter-Efficient Fine-Tuning):
- Fine-tune only a small set of parameters or additional ones to reduce computation and storage costs.
- Common methods:
- Adapter Fine-tuning:
- Insert small adaptive modules between layers of the pre-trained model and fine-tune them while freezing the original model's parameters.
- Advantages: Efficient and flexible, reducing computational costs and memory usage, applicable to multiple tasks.
- LoRA (Low-Rank Adaptation):
- A form of adaptive fine-tuning, fine-tuning a subset of parameters through low-rank matrices, typically adjusting a small subset of weights.
- Most common, recommended, minimal impact on the original model's capabilities.
- BitFit:
- Only fine-tunes bias parameters.
- Adapter Fine-tuning:
- Choosing Layers for Fine-tuning
- Not recommended
- Sub-categories:
- Fine-tuning Last Layers:
- Fine-tune only the last few layers, useful for adding task-specific adaptation while retaining original model capabilities.
- Advantages: Reduces complexity and resource demand, still improves performance for specific tasks.
- Disadvantages: Limited fine-tuning depth, may not fully meet task needs.
- Fine-tuning Last Layers:
- PEFT (Parameter-Efficient Fine-Tuning):
4.2. Based on Task: SFT, RLHF, RLAIF
- Supervised Fine-tuning (SFT): Supervised fine-tuning;
- Reinforcement Learning from Human Feedback (RLHF): Fine-tuning using human feedback through reinforcement learning;
- Reinforcement Learning from AI Feedback (RLAIF): When human feedback is costly, use AI-generated feedback.
4.3. Low-resource Fine-tuning
- LoRA/QLoRA (reduce training parameters)
- Mixed Precision Training (reduces memory usage by half, accelerates training)
- LOMO (greatly reduces memory usage, but may perform worse than LoRA in some scenarios)
- Activation Checkpointing (reduces memory usage at the cost of additional computation)
- Heterogeneous Device Training (reduces memory usage)
4.4. DeepSpeed
Distributed training
- Data Parallelism: When data is too large to fit into one memory unit.
- Model Parallelism: When the model is too large to fit into one memory unit.
DeepSpeed partitions the model across multiple GPUs, handling memory communication to solve the issue of limited memory. It may also temporarily store the model in system RAM (offloading) if required.
5. LoRA and QLoRA
5.1. LoRA
Paper: LoRA: Low-Rank Adaptation of Large Language Models
Paper Link: https://arxiv.org/abs/2106.09685
W + W =
Fine-tuning changes the W parameters, freezing W.
LoRA can be applied to any linear transformation inside the model:
- h = Wx (linear transformation)
- h = (W + W)x
Advantages of LoRA:
- Fewer parameters need to be trained, and changes to existing parameters are minimized (reducing the risk of altering the original capabilities of the model).
- Requires less memory for training.
- Increases training efficiency.
lora_config = LoraConfig(
r=8, # LoRA rank, typically 8 or 16
lora_alpha=32, # New W = Old W + lora_alpha/r * $\Delta$ W (affects weight update scale)
target_modules=modules, # Specify modules for LoRA fine-tuning (usually not all Linear layers are tuned, often QKV layers)
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
5.2. QLoRA
For loading large models into memory.
Quantization: Quantizes the model before loading, e.g., converting from 32-bit to 4-bit to reduce memory usage.
While quantization reduces memory consumption, it leads to some loss in precision and may degrade the model’s performance.
QLoRA addresses memory limitations by applying quantization before loading the model.
6. Fine-tuning Practice
6.1. 3 Key Components
- Model (from Huggingface)
- tokenizer: mapping between tokens and ids
- model
- Data (from Huggingface)
- Parameters
6.2. Advanced Fine-tuning Settings
- Quantization Level (QLoRA)
- 4-bit or 8-bit
- Using quantization reduces the model size, but also reduces precision, which may lead to a slight decrease in performance.
- Acceleration Method
- flash-attention
- Training Method
- SFT (Supervised Fine-Tuning) Instruction Tuning (70%-80% adoption)
- Common alignment methods:
- PPO (Reinforcement Learning approach)
- DPO
- Datasets
- Local datasets
- Datasets from HuggingFace
- LoRA Parameters
- LoRA matrix rank size
- Usually 8 (or 16)
- LoRA scaling factor
- Typically twice the LoRA rank, 16 or 32
- LoRA matrix rank size
6.3. GitHub: tloen/alpaca-lora
GitHub: https://github.com/tloen/alpaca-lora
Training
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \ # Base model
--data_path 'yahma/alpaca-cleaned' \ # Dataset
--output_dir './lora-alpaca' \ # Fine-tuned model output path
--batch_size 128 \ # Parameters from this line down
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]' \
--train_on_inputs \
--group_by_length
Inference
python generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \ # Original parameters
--lora_weights 'tloen/alpaca-lora-7b' # New parameters
6.4. LLaMA-Factory
LLaMA-Factory is a fine-tuning UI interface that wraps various model and parameter configurations, simplifying the code-writing process. You only need to select and configure the options in the UI to begin fine-tuning. You won’t need to write code unless some newly released models are not yet integrated into LLaMA-Factory, in which case you can write your own code.
6.5. More
Rent GPU
- Domestic: AutoDL
- International: jarvislabs.ai
Download Llama model parameters: https://github.com/shawwn/llama-dl
https://github.com/ymcui/Chinese-LLaMA-Alpaca
https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
7. Open-Source Models
English Open-Source Models:
- Llama
- A series of large language models developed by Meta.
- Alpaca: A lightweight, low-cost instruction-tuned model developed by Stanford University based on the LLaMA model. It can perform specific tasks with fewer resources.
- Mistral-7B
- Mixture of Experts (MoE) Mistral 8x7B
Chinese Open-Source Models:
- Qwen
- ChatGLM
- Fine-tuned mainly on 6B models, larger models not open-sourced.
chatglm.cppis a C++ rewrite aimed at running models on CPUs; now most models have a corresponding C++ version (quantized inference solution).
Fully open-source (includes dataset and model weights, datasets not provided for the above models):
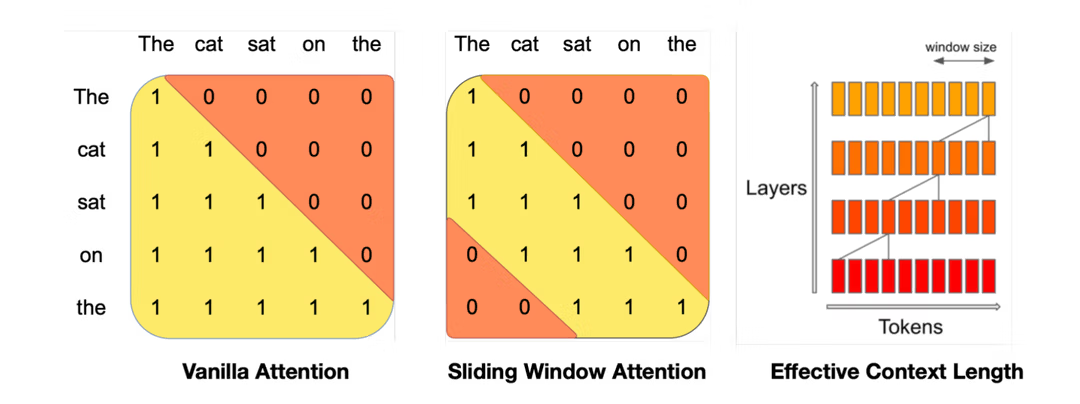
7.1. Mistral-7B
- Uses Sliding Window Attention (SWA) to handle long sequences.
- Uses Grouped-query Attention (GQA) to accelerate inference.
8. Mixture of Experts Model (MoE)
Paper Name: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Paper: https://arxiv.org/pdf/2101.03961
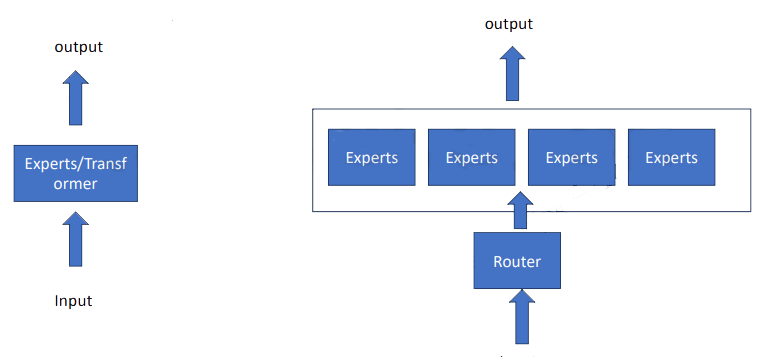
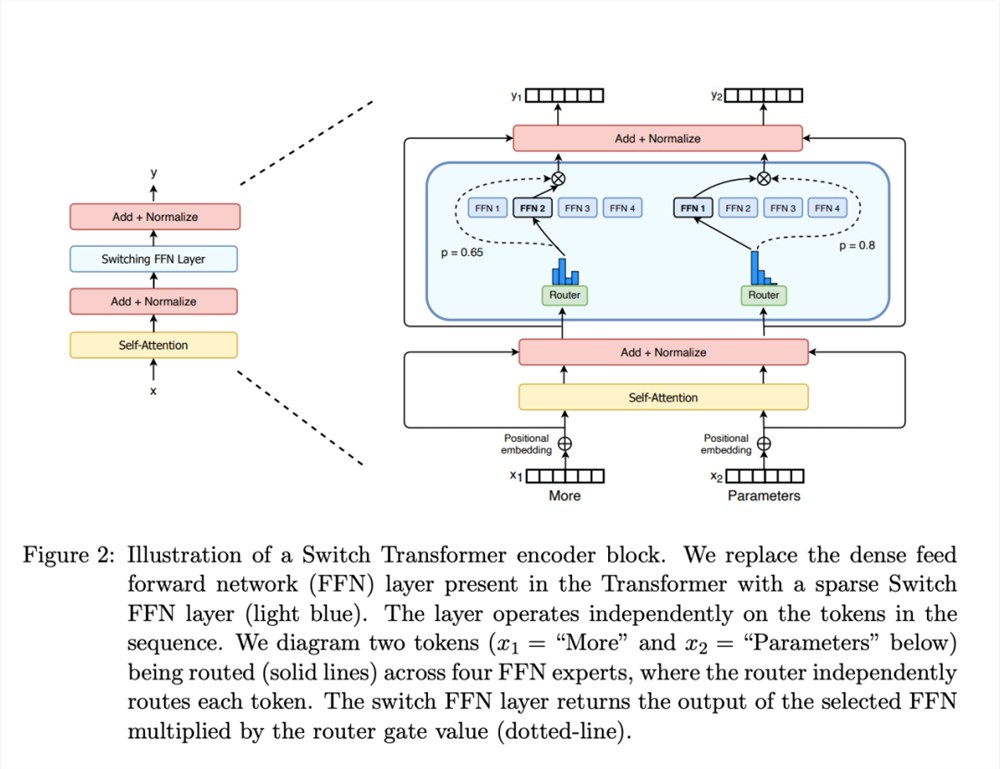
- Multiple experts
- Mistral 8x7B has 8 experts
- DeepSeek’s MoE has 160 experts
- Each expert has its own area of expertise.
- Router (routing selection)
- Softmax is used to determine each expert's weight ratio.
- Sparse Mixture of Experts
- Not all experts are queried at once; only a few are selected.
- Mistral 7B is a sparse mixture of experts model.
- Some modules are shared, while others are separate.
- Mistral 8x7B would have 56B parameters, but with shared modules, it totals around 40B.
- MoE uses a switching FFN layer instead of the original FFN, with other modules shared.
- The MoE layer consists of a gating network and a set number of expert networks.
Despite its advantages of efficient pre-training and fast inference compared to dense models, MoE faces some challenges:
- Training: MoE's pre-training is computationally efficient, but fine-tuning can lead to poor generalization, resulting in overfitting.
- Inference: While MoE may have many parameters, only a portion is used during inference. Inference is much faster than for dense models with the same number of parameters. However, all parameters need to be loaded into RAM, so memory requirements are high.
MoE Advantages
- Computational Efficiency: The sparse selection mechanism avoids having all experts involved in inference, reducing computational complexity. In practice, MoE's computational load can be approximated as , where
kis the number of active experts andnis the input sequence length. - Scalability: MoE is well-suited for large-scale models. By increasing the number of experts, the model's capacity can be expanded without significantly increasing computational costs for inference. This makes MoE particularly suitable for extremely large language models such as Switch Transformers and GShard.
- Flexibility: MoE dynamically selects experts based on input, allowing it to handle different types of tasks and data.
MoE improves model performance and efficiency through the following designs:
- Sparse expert selection reduces computational complexity.
- Gating networks dynamically select experts based on the input.
- Load-balancing loss ensures experts are used efficiently.
9. RLHF (Reinforcement Learning from Human Feedback)
RLHF is a machine learning method that combines reinforcement learning with human feedback to help models adapt better to specific tasks and desired behaviors.
Challenges to address:
- Traditional reinforcement learning faces challenges in reward engineering and lacks high-quality feedback.
- Defining a precise reward function is difficult for many complex tasks.
- Aligning with complex human values.
- How do we evaluate the quality of text generated by GPT? The "goodness" of generated text is based on human values, so how can we teach GPT human values?
Main principles: RLHF consists of four key components:
- Pre-trained model: Starts with a pre-trained model, such as a large language model trained on vast amounts of text data.
- Human feedback: Human feedback is collected to evaluate the quality of the model's outputs, including annotating or scoring the generated text and providing guidance for improvement.
- Reward modeling: Human feedback is used to train a reward model, which learns to score the model's outputs based on human feedback.
- RM (Reward Model)/Preference Model
- Reinforcement learning: The reward model is used as the reward function. Standard reinforcement learning or deep learning algorithms are used to further train the original model, optimizing its outputs to maximize the score provided by the reward model.